Background on the Lesson
While most optical character recognition (OCR) programs allow users to automatically distill text from an image file, in our departmental computer lab we used a software program that also has a “learning” mode, which is meant to help the OCR algorithm learn the characteristics of a particular text, but can, in turn, also be deployed to help humans see how the software makes its recognition choices. I have students try using this mode first, and I provide a particularly messy scanned text for them to work on, in conjunction with an easier text page of their choice. The intended outcome is for students to experience hands-on OCRing and then produce a reflective write-up comparing their OCR experiences and giving their hypotheses about when digitization work best.
This assignment for upper division corpus linguistics students is one of a series of tasks that students do to obtain material for a specialized corpus they will use across several assignments.
It is a first methods course in preparing .txt files that they will use later with concordancing software so that they can then go on to check for the distribution of particular words in their texts, with the goal of finding multiple examples of words in context. For compiling their own mini corpus of texts, they can use a number of available existing public domain text archives, such as Project Gutenberg and the Oxford Text archive. De Smet et al. (2015) have also gathered together texts from these first two sources into several corpora of late modern English texts that can be obtained for free. In the case of more contemporary sources, my students often work on compiling the texts of understudied languages that they are exploring, make plans to use language learner essays, or work from computer-mediated exchanges, such as Tweets and text messages. To do so, they may scrape the web for data, or gather existing textbook examples. Often, they are interested in inputting materials that are only in printed form, or perhaps in an older PDF format. So determining whether they can capture the text from a JPEG or PDF is a valuable first step.
The lesson is meant to take students beyond just clicking on a button to initiate a particular software process. It raises the issue of what text recognition does by making the case for the larger value in understanding the difference between a picture file and a section of recognized text. And it provides them a chance to discuss the tool’s output and to hypothesize why it came about. For the OCR task described here, then, there are two goals: (a) Learn how OCR works in order to assess which documents can best be captured automatically vs. e.g., retyping or using voice input; and (b) Assess what types of characters, diacritics, and physical documents hamper the use of OCR, and speculate on why.
Since screen readers use this same basis for making pictures of printed materials accessible on the web, when students know what is being checked, it also helps them to understand how the content of the internet is made more experienceable for a wide set of users. So they’re grappling with the idea, described in Clemens (1965, 9), in early work investigating the ability of OCR to be used in preparing a reading machine for the blind, of OCR as “the process of classifying the optical signals obtained by scanning a page of printed characters into the same classes a human observer would class them.” Although universal design and providing accessibility via alt text labeling are ideas of growing importance in the 21st century curriculum, the issues behind these decisions are older. So in class we also discuss Hofstadter’s 1982 article that summarizes the issues behind Donald Knuth’s Meta-font idea. That is, how different can a character be and still be recognized (by humans or by computers) as the same letter? And while the class works throughout the semester with a textbook covering general functions of concordancing software (Bowker and Pearson 2002), for this assignment they also read Bowker’s 2002 chapter “Capturing Data in Electronic Form,” which gives a detailed overview of how OCR works.
Examples of the Interactive Mode
Of the many OCR programs available, some are built in the background of text processing packages and phone camera scanners. The interactive “learn” feature in the ReadIris OCR programs was selected for the department lab for its potential for both the user and the algorithm to learn. The software leads students through blocking off graphics from sections of text in a scan of the original document, ordering the text blocks (such as columns, headlines, and page numbers), and then the crucial step, working through the text to determine if any questionable marks are characters in a given alphabet. Figure 1 shows a screenshot of the software’s learning process which has stopped on the numeral 3.
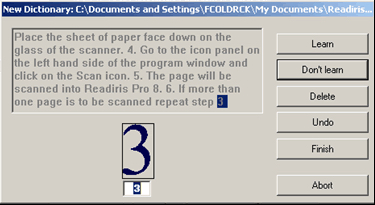
An instruction sheet they work on in pairs in class walks them through the options for the interactive mode. The following steps are distilled from definitions in the software manual (I.R.I.S. 2002, 2.25–27):
- If you choose Learn, the program saves this doubtful character in the font dictionary as final. Future recognition will no longer require your intervention, the shape is considered learned once and for all.
- If you choose Don’t Learn, you have still made a correction, but the status of the newly learned symbol gets the status “unsure” in the dictionary. For future recognition, the system will propose the learned solution but will still require a confirmation. (This button is used for symbols which might be confused with others: a badly printed “e” which might be mistaken for a “c”, a damaged “t” which closely resembles an “r”, etc.)
- The Delete button will eliminate the form from the output. This is used to ignore “noise” in the document—spots, coffee stains, lint, etc. which might get recognized as periods, commas, apostrophes, etc. It is a way to erase unwanted symbols.
- With Undo you can go back to correct mistakes. You can undo the last nine decisions.
Students frequently have a particular language or era of texts that they are studying. To obtain material, they may need to scan in items that only exist as paper pages. Often their first task of scanning in a modern, cleanly printed document goes smoothly, which can reinforce their starting idea that all OCR is easy and automatic. So for an added challenge in grasping how OCR works, I also have them work with types of realia I provide in order to help them come to grips with typical noise in the data, such as decorations, spelling mistakes, grammatical errors, stray marks, non-letter characters, incorrect punctuation, and so on.
Figure 2 shows a page I first chose for a sample, from a Scottish-English dictionary.

As a lesson in OCR challenges, the dictionary scan has text that curves into the gutter, page headings and page numbers, and small letters in the pronunciation key that make it trickier than it first appears for character recognition.
Next, Figure 3 shows a photocopy of a set of three contemporary receipts.

The receipts image has a variety of fonts including dot matrix printing and print that bleeds through from the back of the paper. The receipts had also been wrinkled before scanning. These images are meant to incorporate some frustration at what the human eye easily reads but which may confuse automated text recognition.
The most recent version of the exercise is shown in the appendix, along with the messy text image they worked on, a picture of four magazine ads in Figure 4.

Takeaways
Because students will continue to use a growing body of online resources, I am hoping to raise their awareness of the origins of OCR errors they will likely encounter in the wild. I further hope to provide them with the ability to assess other OCR programs they may use outside of class. That is, one goal is for them to not just learn to use this piece of software, but to speculate on why types of tools give the output that they do. Most crucially, as this is a methods training course for linguists, I hope to instill an informed basis for deciding whether documents that they will be working with are best dealt with by OCR, and if so, how much manual cleanup might be required for their future research.
Insights into whether these experiences about document assessment are happening can be seen from anonymized quotations from student responses in their OCR reflections:
It surprised me just how different an experience it can be simply due to the type of document you are working with, which was highlighted by the two texts I worked with. I can see how quality plays a big role in determining how useful OCR is.
The first text could be easily scanned once placed at the right angle as it encountered few errors. While the text with the four ads had more errors, if I were to encounter an old or damaged text of that quality, it would be faster to record small amounts of the text at a time followed by manual edits in order to keep track of which part of the text is scanned so an accurate transcription of the information can be created.
[A] common mistake was for the letter “w” to be taken as 2 “v”’s which I sometimes had the opportunity to correct mid-program-sequence and sometimes I didn’t have that opportunity. I would categorize these errors as misinterpretations of letter boundaries. The last main issue, is that the program didn’t recognize word boundaries for several paragraphs and so in true Latin style, recorded all the letters without spaces.
The OCR software was an interesting task, with various challenges to overcome throughout the process of converting an image to text… it should be said that it is not always possible to possess a perfect file for the software to process, and in that case it simply means much more work will need to be put into it, but it’s overall a ratio between (quality of the image : time spent working on the document).
For their first test document, students often chose textbook pages or excerpts from novels, sometimes in a language requiring non-English characters. The fact that they controlled some of the text choices, but shared the more challenging English text image with their classmates, led to their being invested in their assessments and provided a chance to confer with classmates. Over time, I changed out the images, trying to make sure the messiest documents did not become completely discouraging. Generally, however, students reveled in the contrast between their cleaner and messier texts.
The goal is not for them to use only this company’s product moving forward, or to stay in the interactive mode for all their work. Rather, it is to use this experience to fill in their understanding of the mechanism behind any OCR they use later (e.g., ABBYY Finereader, Adobe Acrobat, Tesseract), so that they become familiar with what happens when they use OCR at home through a combined text processing package, via scanners at the library, etc. Ultimately, seeing the behind-the-scenes effects from diacritics, typefaces, and varying document quality helped deepen their understanding of a process that they originally took to be automatic.
